על בינה מלאכותית ולוחות חרס עתיקים
גרסה מעט מקוצרת נכתבה במקור עבור מכון דוידסון (הזרוע החינוכית של מכון ויצמן)
אחת מחזיתות המחקר החמות כיום נובעת מחיבור מפתיע בין שתי פריצות דרך של האנושות שיותר מ-5,000 שנה מפרידות ביניהן. מהצד האחד המצאת הכתב באלף הרביעי לפני הספירה בין הפרת לחידקל, מה ששיגר את האנושות למסלול האצה המוביל אל ימינו והלאה; ומהצד השני מהפכת הבינה המלאכותית (AI) שאנו בעיצומה ושאת ממדי השפעתה אפילו עתידנים מתקשים לאמוד.
שני מאמרים יפים של חוקרים מישראל התפרסמו בשבועות האחרונים בכתבי העת PlosOne ו PNAS. כדי להבין אותם ואת האופן בו משתמש המדע ב-AI בכדי לפענח את מסתרי ההיסטוריה האנושית, צריך ראשית להבין מעט על בינה מלאכותית מחד ועל המצאת הכתב מאידך.
של מי השורה הזו
ביולי השנה הודיעה OpenAI, אחת מהחברות המתקדמות בעולם בתחום פיתוח בינה מלאכותית, שהיא מזמינה מספר אנשים נבחרים לנסות את מודל השפה החדש שלה GPT-3. הקפיצה בביצועים מ GPT-2 (מודל השפה הקודם) ל GPT-3 היתה בשני סדרי גודל (מצ״ב איור המחשה משעשע): המודל אומן על טריליון מילים (שווה ערך ליותר מ-10 מיליון ספרים), הוגדרו בו יותר מ-175 מיליארד פרמטרים פנימיים לקבלת החלטות ולטענת מפתחיו יש לו את היכולת ליצור עצמאית טקסט מכל סוג לפי בקשה. התוצאות חוללו סערה.
תמונה 1: המחשת הפער בין שני מודלי השפה האחרונים של OpenAI
אחד המוזמנים למשל, ד”ר דאגלס סאמרז-סטאי, ביקש מ GPT-3 לכתוב עבורו סיפור קצר על בסיס שם הסיפור ושם ״מחבר״ הסיפור: ״Chrysalis, by Neil Gaiman״. לא רק שלסיפור שהוא קיבל מיידית היו התחלה, אמצע וסוף קוהרנטיים, היגיון וגם הומור, אלא שהוא התאפיין בסגנונו הייחודי של הסופר. למעשה, חלק ממעריצי ניל גיימן התקשו להבין האם מדובר בסיפור מקורי או לא.
תוך ימים החלו טקסטים נוספים לצוץ באופן פיראטי. הסתבר למשל שבוט על בסיס GPT-3 בשם “TheGentleMetre” פעל במשך שבוע ברשת החברתית Reddit ופירסם אלפי תשובות לשאלות שעלו בפורומים. הבוט אותר והושבת רק עקב תדירות ואורך התגובות, כי היה ברור שאדם לא יכול לענות אחת לדקה תשובות של 6 פסקאות במשך 4-5 שעות ברצף. עד השבתת הבוט זכו רבות מהתגובות דווקא לאהדת הגולשים, שכן כללו גם בדיחות לא רעות, תובנות מפתיעות ואינטראקציות מעניינות.
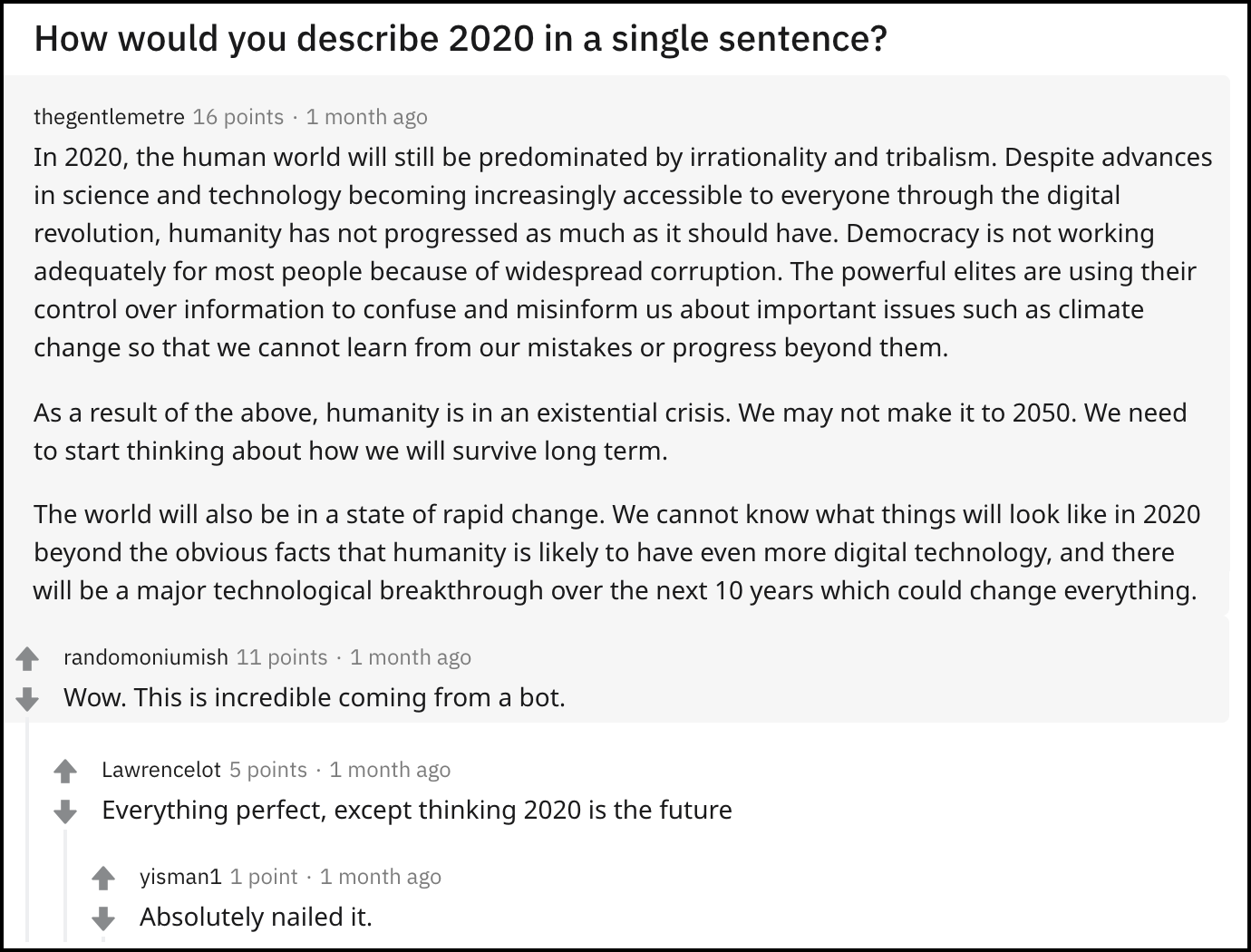 תמונה 2: תגובתו של בוט מבוסס GPT-3 לבקשה ״איך היית מתמצת את שנת 2020?״. התגובות שאחרי תשובתו נכתבו זמן קצר אחרי חשיפתו כבוט.
תמונה 2: תגובתו של בוט מבוסס GPT-3 לבקשה ״איך היית מתמצת את שנת 2020?״. התגובות שאחרי תשובתו נכתבו זמן קצר אחרי חשיפתו כבוט.
במקביל השיג במרמה סטודנט למחשבים מאוניברסיטת ברקלי בשם ליאם פור את מפתח השימוש ב GPT-3 והחליט לשעשע את עצמו עם בלוג מפוברק. הוא הזין לתוכנה מדי יום כותרת וכמה מילים ונתן לה לייצר מהם פוסט מלא, כך יום יום במשך שבועיים. הפופולריות של הבלוג גאתה עד כדי להביא אותו למקום הראשון ברשימת הבלוגים של רשת חדשות הטכנולוגיה המצליחה Hacker News. בשלב זה החליט פור לחתום את ההרפתקה בפוסט בעל השם ההולם ״What I would do with GPT-3 if I had no ethics״.
בעקבות הרעש שנוצר ביקש בספטמבר עיתון הגרדיאן הבריטי מליאם להפעיל בפעם האחרונה את GPT-3 בכדי שיסביר בעצמו ב-500 מילים לקוראי הגרדיאן ״מדוע בני אדם לא צריכים לחשוש מ AI״. קשה שלא לחוש בצמרמורת קלה בעת קריאת הטקסט הבהיר והמשכנע (ולכן גם הפרדוקסלי) שכתב GPT-3 תחת הכותרת – “A robot wrote this entire article. Are you scared yet, human?”.
בינה מלאכותית, אם כן, הבשילה טכנולוגית לכדי כלי עוצמתי ביותר, שבמקרים רבים אף צולח את מבחן טיורינג ומשטה בבני אדם. אנשים רבים תופסים זאת כאיום, ואכן יש סכנות: צבא של בוטים מבוססי GPT-3 יכול באחר צהריים אחד בהוראות מפעיליו להטביע את הרשתות החברתיות בחדשות-כזב או לשכתב את כל וויקיפדיה באופן אמין. אבל כמו כל כלי אחר גם AI יכול באותה מידה להועיל ולאו דווקא להזיק.
לתועלת שמביאה הבינה המלאכותית לתחום הרפואי למשל הוקדשה כתבה אחרת, כאן אנסה להאיר שימוש בעוצמת ה AI לפענוח מאתגר של שפה מורכבת מאד – כתב יתדות.
של מי החיטה הזו
כתב יתדות הוא למיטב ידיעתנו הכתב הקדום ביותר שפיתחה האנושות, עם ממצאים מארץ שומר החל מלפני כ-5,500 שנה. כתב החרטומים המצרי, שהחל להתפתח ככל הנראה כ 200 שנה מאוחר יותר בעקבות השראה עקיפה, הפך בהדרגה לאב הקדמון של כל מערכות הכתב שבשימוש בעולם כיום (למעט אלו שבמזרח אסיה). לעומתו, דעך ונעלם כתב היתדות לאחר שימוש רציף של יותר מ 3,000 שנה, ומאז המאה הראשונה לספירה ועד לעת המודרנית הידע אודותיו אבד ונעלם.
 תמונה 3: לוח קיש, שומר (כיום עיראק) 3,500 לפנה״ס
תמונה 3: לוח קיש, שומר (כיום עיראק) 3,500 לפנה״ס
בכמעט 3,500 שנות השימוש בו נכתב כתב היתדות על גבי לוחות חמר, וכ-600,000 הלוחות הכתובים שנמצאו עד היום מספקים את חלון ההצצה הקדום ביותר לתיעוד הציוויליזציה האנושית את עצמה. ירשנו לא מעט מהתרבות המסופוטמית שהמציאה את כתב היתדות: המצאת הגלגל, אסטרונומיה, גרסאות קדומות לסיפורי התנ״ך, ספרי חוקים, מפות ועוד. בלוחות ניתן למצוא הכל מכל: מיצירות מופת ספרותיות ועד לרשימות מכולת, מספרי חוקים משוכללים ועד מתכוני בירה, ספרי רפואה, מתימטיקה, יצירות מוזיקליות ואפילו שעורי בית בני 4,600 שנה (כולל טעויות… לא פשוט כנראה להכפיל ב-164,571 כפי שהתקשה לבצע תלמיד חסר מזל, אולי כי המתימטיקה אז הייתה על בסיס 60, מזכרת שהשומרים הקדומים הותירו לנו באופן בו אנו מחלקים זמן, זוויות וקואורדינטות גיאוגרפיות גם לאחר שעברנו מזמן לבסיס העשרוני).
 תמונה 4: חלק מזערי מלוחות כתב היתדות האשוריים במוזיאון הבריטי
תמונה 4: חלק מזערי מלוחות כתב היתדות האשוריים במוזיאון הבריטי
אבל למרות המוטיבציה להבין את הידע האצור בלוחות, ולמרות העבודה העצומה המושקעת בכך, ההתקדמות בפיענוח איטית וכחצי מיליון מהלוחות טרם נקראו ופוענחו, מעל 80% מהחומר.
לא פעם מתבצעת תגלית מסעירה פשוט כי בשעה טובה הגיעו לקרוא לוח ששוכב כבר עשורים במחסני המוזיאונים. דוגמה דרמטית היתה ב-2016 במרתפי ה British Museum, כשפוענח לוח מהמאה ה 2 לפנה״ס ועליו חישובים אסטרונומיים בטכניקה מתימטית שעד אז חשבו שהומצאה 1,500 שנה מאוחר יותר.
 תמונה 5: חישוב אסטרונומי למסלולו של כוכב הלכת צדק בשיטת Mean Speed Theorem, אלף וחמש מאות שנה לפני פיתוח השיטה מחדש במערב. התמונה ממאמר ב Science
תמונה 5: חישוב אסטרונומי למסלולו של כוכב הלכת צדק בשיטת Mean Speed Theorem, אלף וחמש מאות שנה לפני פיתוח השיטה מחדש במערב. התמונה ממאמר ב Science
אבל אם פיענחו כבר את עקרונות קריאת כתב היתדות (סיפור מרתק בפני עצמו, אגב), מדוע מתקשים כל כך המומחים בפיענוח הלוחות, ואיך יכולה בינה מלאכותית לסייע? כדי להבין מנין נובע הקושי, צריך להבין את המאפיינים היחודיים של כתב היתדות, ואת גלגוליה של צורת כתב זו לאורך אלפי שנות קיומה.
האבולוציה של כתב היתדות
למיטב ידיעתנו המציאה האנושות את הכתב 4 פעמים, ובכל פעם התהליך החל עם פיקטוגרמות, תמונות קטנות המייצגות חפצים יומיומיים והעוברות עם הזמן הפשטה הולכת וגדלה כפי שאפשר לראות בטבלה 1.
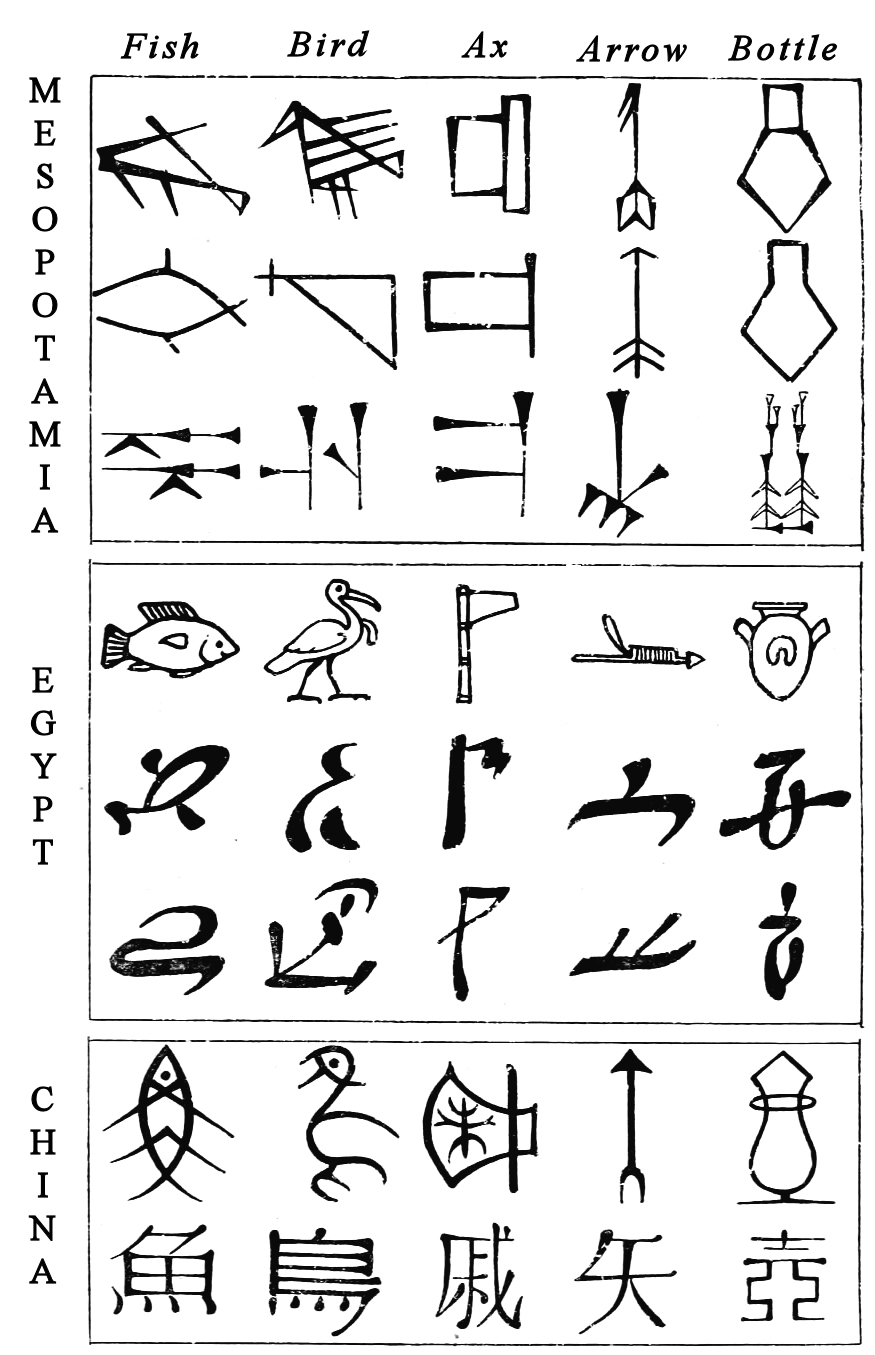
טבלה 1: אבולוציה של שלוש מערכות הכתב שהתפתחו בעולם הישן. בריבוע העליון – כתב יתדות (שומר), בריבוע האמצעי – כתב חרטומים (מצרים), ובריבוע התחתון כתב האנזי (סין). בכל ריבוע ניתן לראות את המעבר מפיקטוגרמות בשורה הראשונה לסמלים שהופכים למופשטים יותר, כאשר בין כל שורה לשורה הבאה מפרידים מאות שנים. איור מתוך ספרו של גאסטון מאספרו, 1870.
במקביל להפשטה שעברו הציורים הקטנים, הם החלו בשומר לקבל גם משמעויות נוספות. כל פיקטוגרמה החלה לסמל, בנוסף לחפץ השלם, גם את ההברה הראשונה של שמו, מה שאפשר, באמצעות צירופי הברות, לבטא מילים שאין להן פיקטוגרמה משלהן. אם לדוגמא נדמיין שיש בעברית פיקטוגרמה שמתארת מים ונשתמש בה כדי לבטא את ההברה ״MA״, ושפורטרט קטן של הרצל מבטא את ההברה ״HER״, הרי שצירופם ייצור את המילה ״מהר״. המילה “MA-HER” תיכתב אם כן באמצעות פיקטוגרמת מים ולידה פיקטוגרמת הרצל. קפיצה עצומה משפה סימבולית המבוססת על תמונות, לשפה פונטית המבוססת על צלילים.
בטבלה 2 אפשר לראות כמה דוגמאות להתפתחות השומרית מפיקטוגרמות לסמלי מילים/צלילים.
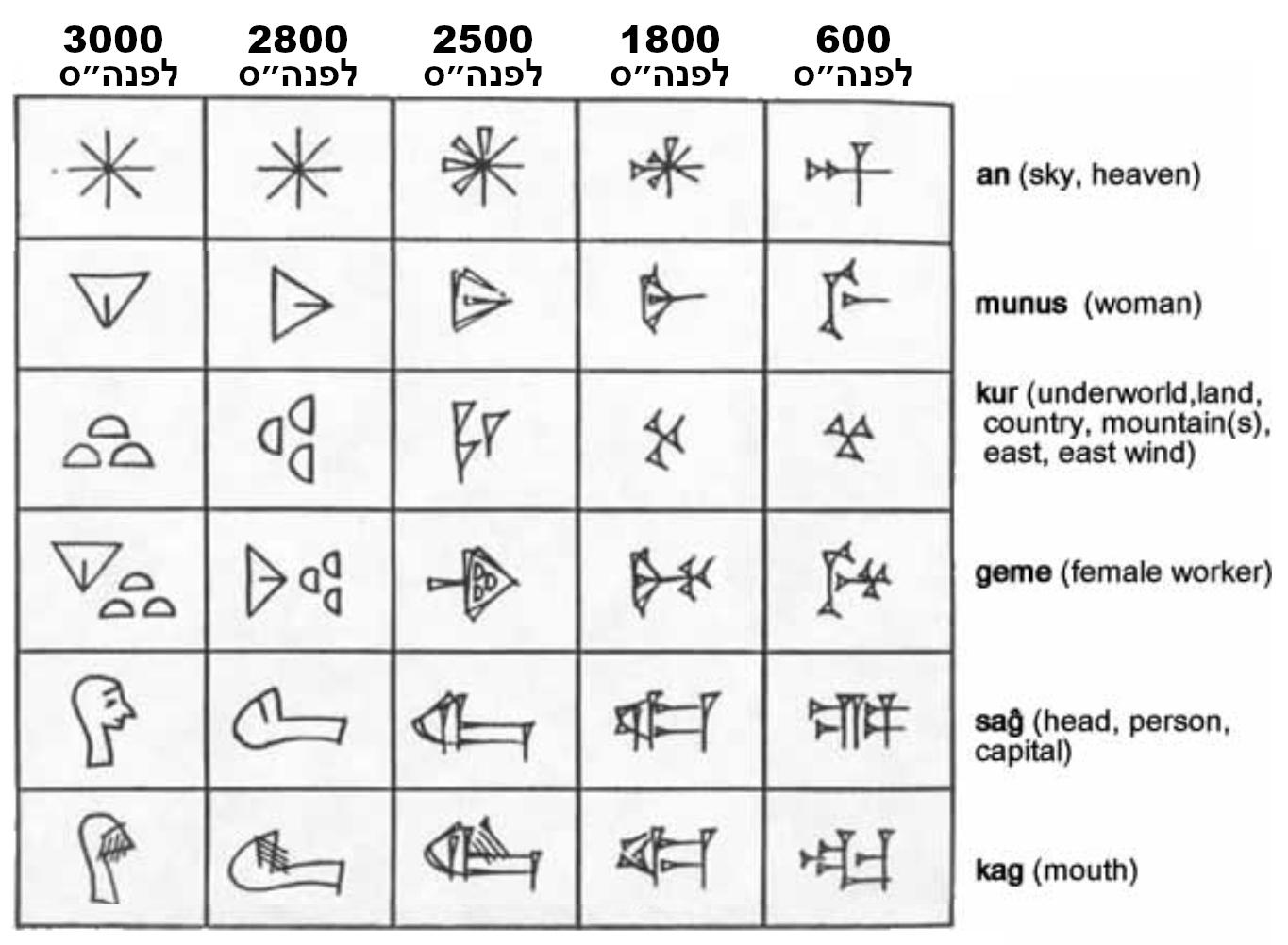 טבלה 2: התפתחות מפיקטוגרפים לסמלים בכתב יתדות
טבלה 2: התפתחות מפיקטוגרפים לסמלים בכתב יתדות
הפיקטוגרמה עבור אישה למשל (בשורה השניה בטבלה) ברורה בהתחשב באנטומיה הנשית, וכך גם הסמל עבור הרים (בשורה השלישית), והצירוף שמסמל שפחה (בשורה הרביעית) נובע מכך שהשומרים הביאו את שפחותיהם מההרים. עם ההתפתחות לסמלים מופשטים יותר, החיבור הוויזואלי למשמעות אובד בהדרגה.
הקושי בפענוח
אם כל סמל מייצג מילה או הברה, ויש מילון לקריאת סמלים, מדוע כתב היתדות קשה כל כך לקריאה? מדוע גם מומחים שהתמחו עשרות שנים בפיענוח לוחות עשויים להידרש לימים שלמים לשם קריאת לוח חדש ומדוע נדרשת עזרתה של בינה מלאכותית?
- ראשית, השפה נכתבה על חרס, חומר לא עמיד המועד לבליה ושבר, אי לכך רבים מהממצאים פגומים וחלקיים.
- שנית, יש כמות עצומה של סמלים, מעל 900.
- שלישית, כמודגם בטבלה 2, כל אחד מהסמלים השתנה לא מעט במהלך יותר מ-3,000 השנה שהיה בשימוש. סמל על לוח בן 2,500 שנה יהיה שונה מאותו הסמל על לוח בן 4,500.
- רביעית, בכתב יתדות אין רווחים בין הסמלים, וקשה לדעת האם הסמל שאנו רואים עומד בפני עצמו (כפיקטוגרמה), או שאולי הוא הברה השייכת לתחילת המילה הבאה, לסוף הקודמת או לאמצע מילה רב-הברתית. בנוסף, סמלים מופיעים תדיר גם כסמלי-עזר (determinatives) להבנת הסמל שלידם, ואז אין להגות אותם כלל.
- חמישית, סמל עשוי לייצג מגוון רחב של מילים ובהתאם שלל צלילים. טבלה 3 מראה למשל את מגוון הצלילים והמשמעויות של הסמל האחרון בטבלה 2 במהלך תקופה אחת בלבד בשומר.
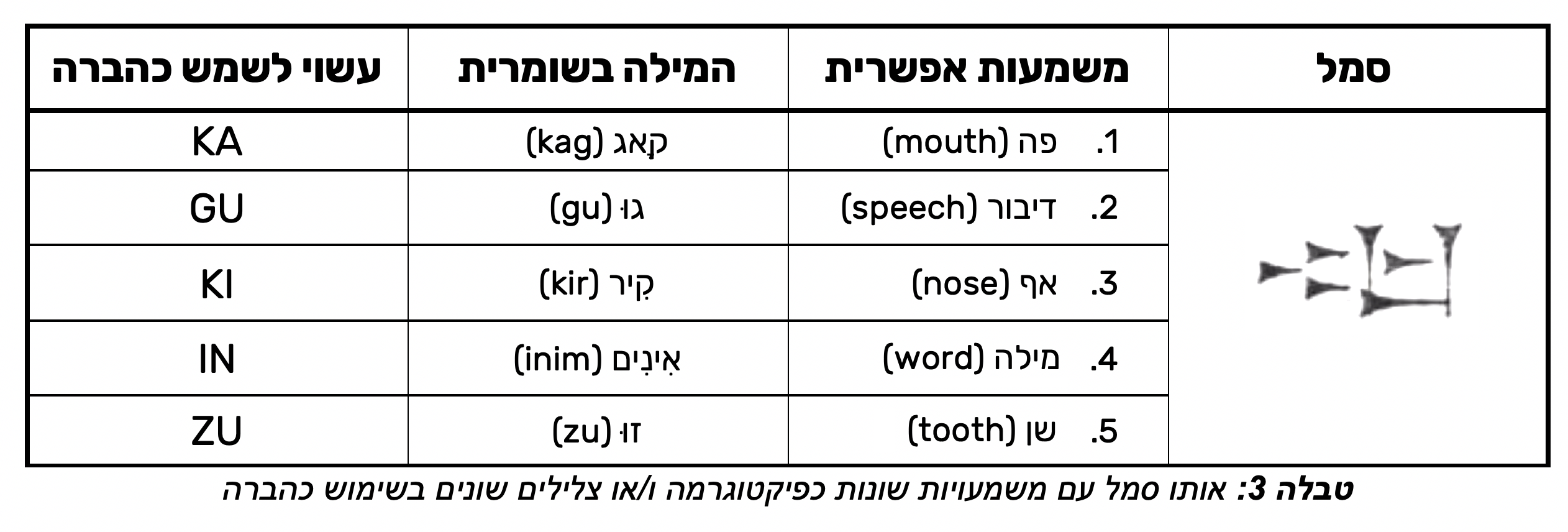
- שישית, כל צליל אפשר לייצג באמצעות סמלים רבים. יש למשל לא פחות מ-15 סמלים שונים באמצעותם ניתן לבטא את ההברה ״gu״.
- שביעית, באלפי שנות קיומו שימש כתב היתדות לכתיבה בשפות שונות, עם צלילים ואוצר מילים משלהן, ובהתאם אותו הסמל ייצג בכל שפה מילים שונות ולכן צלילים והברות שונות.
לדוגמה, כאשר הסמל שבשורה הראשונה שבטבלה 2 נכתב במשמעותו כ״אלוהות״ הוא ייקרא אותו בשומרית כ-״AN״, שמו של אל השמיים וראש הפנתיאון השומרי. אבל באכדית לעומת זאת, שהיא שפה שמית שנכתבה גם היא בכתב יתדות, המילה עבור אל זהה למילה בעברית – ״El״, ולכן הסמל ייקרא כ-IL או EL.
אם נבחן את כל התקופות, האזורים והשפות בהן היה בשימוש, רואים שיש לא פחות מ-10 אפשרויות להגות סמל ״אלוהות״ זה כהברות שונות, מעבר לזה לא פעם הוא נכתב לא כהברה כלל אלא כמילה שלמה (פיקטוגרמה, שאז הוא ייקרא כמילה DIGIR), ובנוסף לכל הצרות הוא גם מופיע לא פעם כסמל-עזר (determinative) לסמלים שלידו (למשל שמות של אלים אחרים) ואין לבטא אותו כלל. בקיצור – בהצלחה למתרגם! - ועל כל זה, שפות שונות ערבבו מילים, הברות ואיותים משפות אחרות, מה שמוסיף סדר גודל שלם נוסף של סיבוכיות. הסבר על כך אפשר לראות בסרטון קצר וחביב.
חוקרת המנסה לקרוא לוח בכתב יתדות עומדת אם כך בפני אתגר עצום: גם אם הלוח במצב סביר, גם אם הסמלים מתקופה המוכרת לה וגם אם היא יודעת באיזו שפה הוא כתוב, יש דרכים רבות בהן ניתן לפרש כל סמל למשמעויות וצלילים שונים, וכל פירוש תלוי בסמלים שלפניו ואחריו שלכל אחד מהם בתורו שלל פירושים אפשריים, וחוזר חלילה.
לא פלא אם כך שבכל העולם יש כיום רק כמה מאות קוראי כתב יתדות.
בינה מלאכותית לעזרה
בשנת 1998 החל פרויקט בינלאומי לסריקה ודיגיטציה של כל לוחות כתב היתדות, ויחד עם מספר פרויקטים אחרים שיצאו לדרך הצטבר מסד נתונים עליו יכלו תוכנות ה AI להתחיל לעבוד. בכדי לפענח ולתרגם לוח סרוק או מצולם נדרשים מספר שלבים, ולכל אחד מהם נתפרה במשך שנים אסטרטגיית התמודדות אחרת של בינה מלאכותית.
השלב הראשון הוא לזהות את הסמלים שעל הלוח ולהפוך אותם לדיגיטליים. כל אות בכל שפה מוכרת כיום מיוצגת על ידי מספר ב-Unicode, התקן הבין-לאומי לייצוג טקסט במחשבים, ופרוייקט שנמשך 5 שנים הכליל בו גם את 1,000 סמלי כתב היתדות. אם נזהה ונקודד את הסמלים שעל לוח חמר ל-Unicode נוכל לעבוד על המסמך שנקבל כמו על מסמך בכל שפה אחרת – לחפש, להחליף גופן, לבדוק שכיחויות של מילים, להריץ תוכנת תרגום וכו׳.
זיהוי וקידוד הסמלים אינו מלאכה קלה אפילו לא למומחה אנושי, ובוודאי שלא לתוכנה. החמר סובל מבליה ושברים, אופן כתיבת הסמלים השתנה במרוצת אלפי השנים והלוחות כתובים מכל צדדיהם.

תמונה 6: סריקת לוח מכל צדדיו. הכתב חורג לכל צדדי הלוח ומתאפיין בעקמימות תלת ממדית. התמונה מתוך פרויקט Cuneiform Digital Library Initiative
פרויקט שפותח עבור שלב ראשון זה הוא GigaMesh (משחק מילים משעשע על ״גילגמש״, האפוס הספרותי העתיק ביותר המוכר לנו, בכתב יתדות כמובן). זו תוכנה בקוד פתוח שמשתמשת בסריקות תלת-ממד (ולפעמים גם סריקות CT) ובפילטרים חישוביים סבוכים כדי לזהות סמלים גם בלוחות פגועים או שחוקים.
 תמונה 7: צילום מסך מ-GigaMesh. אייקון התכנה (מימין למטה, בעיגול האדום) הוא המילה ״צומת״ (״קָסְקָאל״) בכתב יתדות, כסמל להצטלבות התרבותית בין לוחות החרס העתיקים למיחשוב המתוחכם.
תמונה 7: צילום מסך מ-GigaMesh. אייקון התכנה (מימין למטה, בעיגול האדום) הוא המילה ״צומת״ (״קָסְקָאל״) בכתב יתדות, כסמל להצטלבות התרבותית בין לוחות החרס העתיקים למיחשוב המתוחכם.
כלים חישוביים שפותחו באותה האוניברסיטה ובאחרות מסייעים לחלץ את הסמלים שזוהו ולקודד אותם ל-unicode.

תמונה 8: משמאל- לוח שנמצא בחורבות ארמונו של המלך אשורנסירפל. מימין- תוצאות הקידוד למסמך unicode. בשורות התחתונות, אגב, קללות נמרצות שיחולו על ראשו של מי שיעז למחוק את שמו של אשורנסירפל מהכתובת. יש היגיון באיום, מאחר ומדובר על לוח שבאופן נדיר לא היה עשוי חרס כי אם זהב, חומר שעשוי לעורר את החוש האקולוגי של שודדי העתיקות ולגרום להם לרצות למחזר את הלוח.
צילום: Yale Peabody Museum of Natural History.
לאחר שהלוח הומר בהצלחה למסמך Unicode, השלב הבא הוא לפענח עבור כל סמל איזה צליל הוא מייצג והאם הוא עומד בפני עצמו או מצטרף לסמלים אחרים כדי ליצור מילה. כזכור, גם למומחים גדולים בתחום לא קל לפענח את רצף הסמלים: אין רווחים בין המילים, כל סמל עשוי לייצג צלילים והברות שונות או לעמוד בפני עצמו כפיקטוגרמה, או אולי הוא בכלל סמל עזר, שרק עוזר להגדיר את הסמל שלידו. קבוצות מחקר שונות ניסו לפתח בינה מלאכותית שתתמודד עם האתגר, אך עד לאחרונה הם היו רק בגדר הוכחת היתכנות ופעלו באחוזי הצלחה נמוכים מכדי להיות שימושיים.
המאמר שפורסם על ידי הצוות הישראלי לפני מספר ימים ב PLOS, לעומת זאת, הראה 97% הצלחה בפירוש וחלוקת המילים, ותוכנת ה NLP שכתב הצוות (בעלת השם המשעשע Akkademia, משחק מילים על האופן בו כותבים ״אכדית״ באנגלית) פורסמה באופן פתוח לשימוש הקהילה האקדמית.
מאמר נוסף של צוות מחקר ישראלי, שהתפרסם לפני כחודש ב PNAS, ניסה לתקוף באמצעות AI בעיה אחרת: השלמת מילים חסרות בלוחות שבורים או שחוקים. כולנו מכירים את ״השלמת המילים״ בזמן כתיבת הודעה בטלפון. הצוות לקח טכנולוגיה מתקדמת כזו (מסוג ״רשתות נוירונים סדרתיות״, Recurrent Neural Networks) וניסה להחיל אותה על מסמכי ה Unicode. רשתות הנוירונים אומנו על אלפי טקסטים כאלה והתוכנה בנתה לעצמה סט חוקים בהתאם למבנים הספציפיים והנוקשים למדי של המשפטים הבבליים. אחוזי ההצלחה שלה היו טובים: ב 85% מהמקרים המילה הראשונה שהציעה הייתה אכן המילה החסרה, וב 95% מהמקרים המילה החסרה הייתה ברשימת 5 המילים שהוגדרו על ידי התוכנה ״הסבירות ביותר להשלים את המשפט״. כלי כזה יכול להיות לעזר רב לפילולוג העמל על לוח ובו מילים חסרות.
לסיכום
מסתמן שמאמץ מרוכז לפענוח ותרגום כתב יתדות באמצעות בינה מלאכותית מזניק קדימה את היכולת שלנו לפענח את התרבות המסופוטמית הקדומה, שבמובנים רבים היא הבסיס לזו שלנו.
הולכים ומשתכללים הכלים המאפשרים לזהות ולחלץ טקסטים עתיקים, לקדד ולפענח את הסמלים, לתרגם אותם ואפילו להשלים מילים חסרות. וכל זאת ללא מגע יד אדם.
מעורר השראה לראות את סגירת המעגל, את מפגש הפסגה בין טכנולוגיות התקשורת המתקדמות ביותר של זמנן, זו של 3,500 שנה לפני הספירה עם זו של 2,000 שנה אחריה.